使用 Rust 构建云原生数仓 Databend
本篇文章是对 Databend 在 RustChinaConf 2022 上演讲的一个全文回顾。涉及「Databend 的架构和设计」以及「Databend 团队的 Rust 之旅」。
Databend 简介
那么,在进入正题之前,让我们先来回答这样一个问题:“什么是 Databend”?
什么是 Databend

官方的说法是:Databend 是一个使用 Rust 研发、开源、完全面向云架构的新式数仓。
借用当下大数据分析领域最流行的两个数据库产品打个比方:Databend 就像是开源的 Snowflake 或者说云原生的 Clickhouse 。
Databend 特性
作为新式数仓,Databend 有哪些基本特性呢?

- 首先是弹性:得益于存算分离的架构与设计,Databend 完全可以做到按需、按量弹性扩展。
- 而向量化执行引擎、单指令流多数据流(SIMD)、大规模并行处理(MPP),共同为 Databend 的性能保驾护航。
- Databend 的存储引擎受 Git 启发,使用快照存储数据。支持
TIME TRIVAL,可以轻松回滚到任意时间节点。 - 另外,近年来经常提的一个词叫“海量数据”,在这些数据中,由各种各样程序产生的半结构化数据是占到相当大一部分比重的。Databend 内置 ARRAY, MAP, JSON 这些数据类型,能够帮助用户进一步发掘半结构化数据的价值。
- 作为一个新生数仓,不管从研发还是客户的角度上,都非常关心生态问题。Databend 使用 SQL 语句进行查询,并且对 MySQL 和 ClickHouse 协议进行兼容,从而与现有工具和 BI 系统无缝集成,比如数据科学家喜欢的 Jupyter、以及用于生成图表的 Metabase 。
Databend 架构与设计
刚刚介绍了 Databend 的一些基本信息,接下来,让我们一起走进 Databend 的架构和设计。看看一个存算分离的云原生数仓该是什么样子。
总览
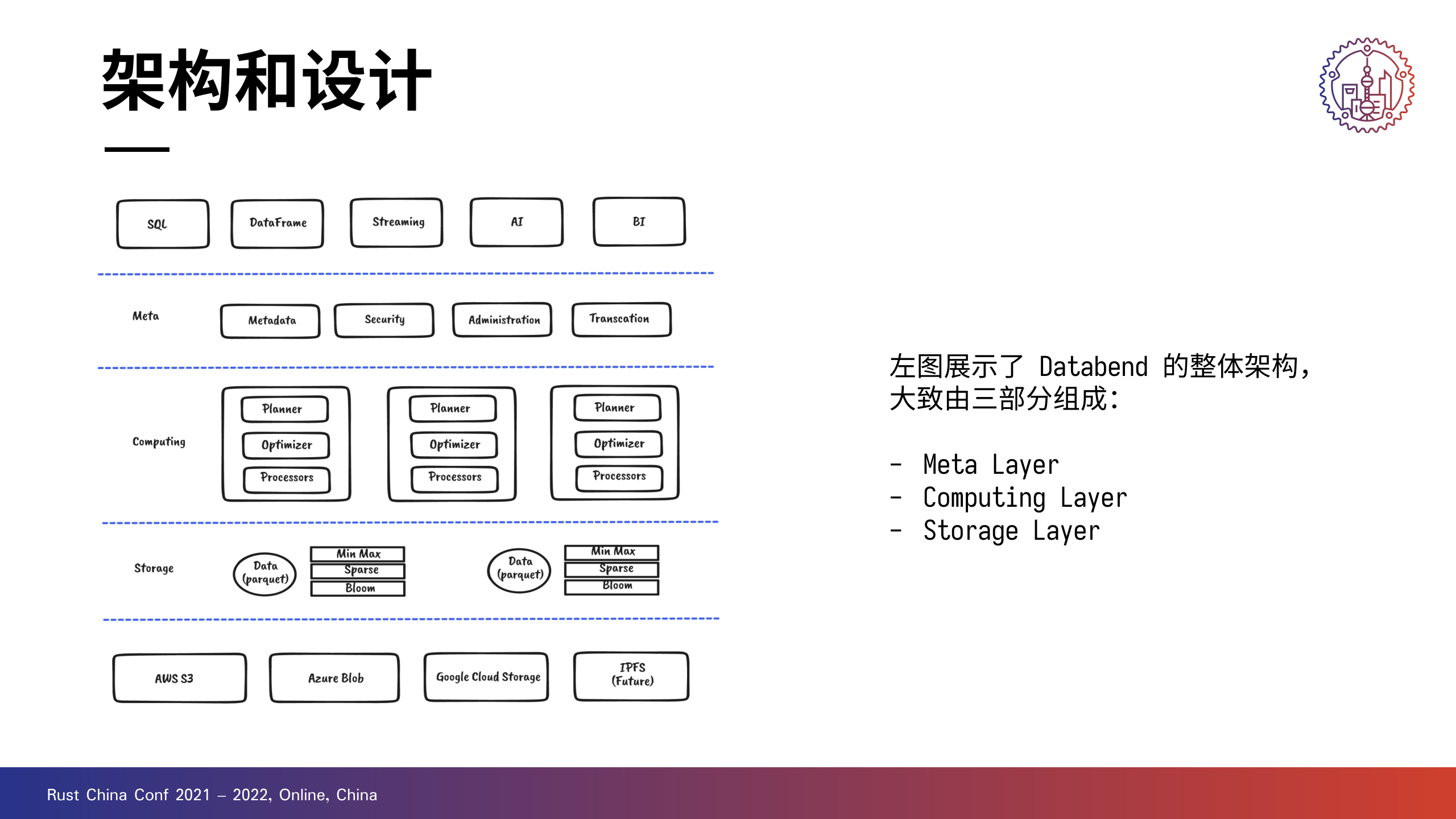
左边是 Databend 的一个架构图。
最上一层对接 AI、BI 等应用,最下一层打通 S3、GCS、IPFS 等存储系统。中间三层则是 Databend 的主体部分。
Databend 可以分成 Meta、Computing 和 Storage 三层,也就是元数据、计算和存储。
说是存储层,其实叫做数据访问层更贴切一些。
架构与设计 - Meta

Meta 是一个多租户、高可用的分布式 key-value 存储服务,具备事务能力。
它会负责管理元数据,像索引和集群的一些信息;Meta 还具备租户管理的能力,包括权限管理以及配额使用统计。
当然,安全相关的部分也由 Meta 承担,比如用户登录认证。
架构与设计 - Computing
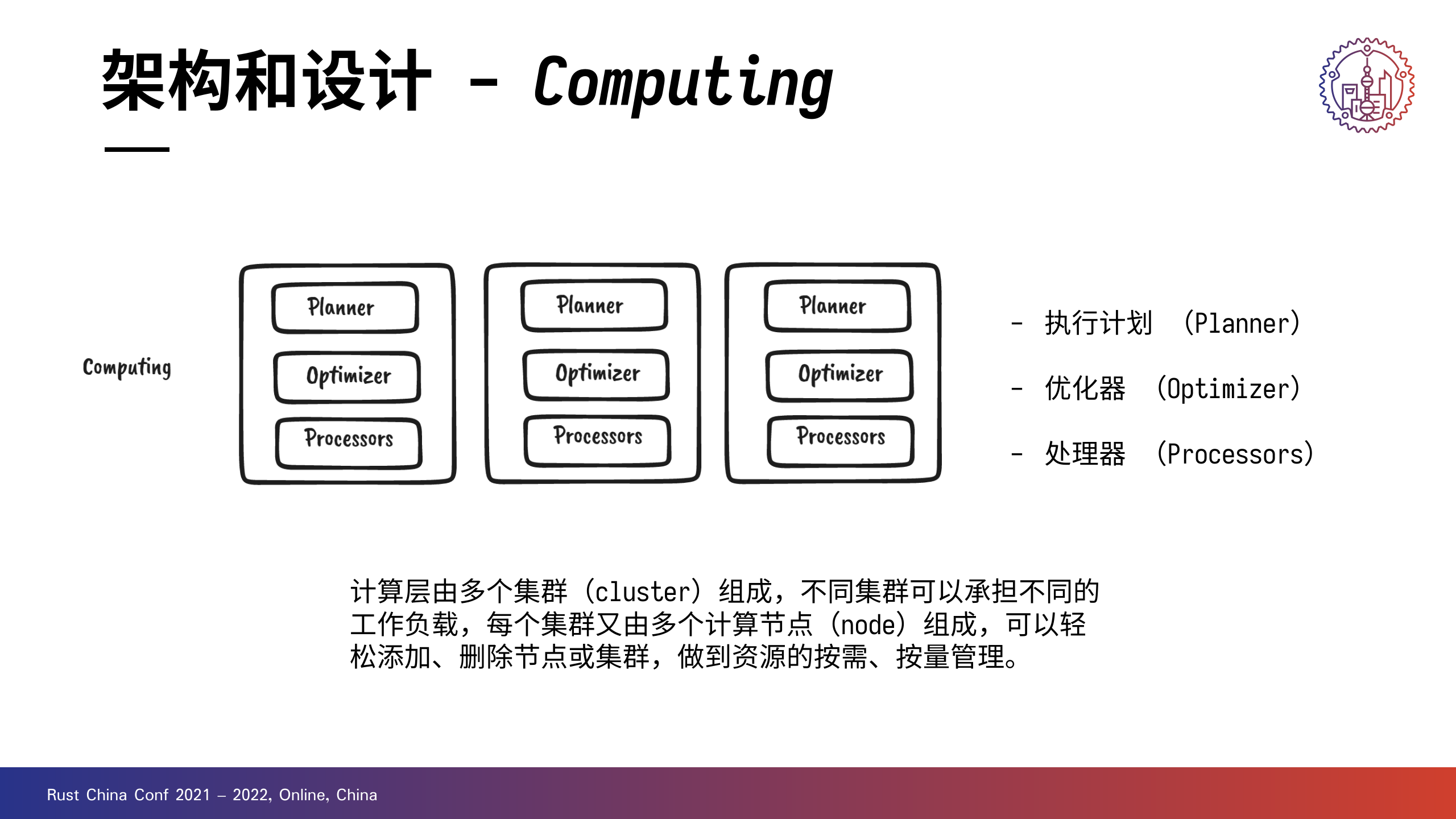
计算层可以由多个集群组成,不同集群可以承担不同的工作负载。每个集群又可以由多个计算节点(node)组成。
计算层中的核心组件有三个:
- 执行计划,也就是 Planner :用于指导整个计算流水线的编排与生成。
- 优化器,Optimizer:基于规则做一些优化,比如谓词下推或是去掉不必要的列。
- 处理器 (Processors)是执行计算逻辑的核心组件:Databend 最近还落地了 Pull & Push 模型的流水线,大幅提高了处理器的执行效率。整个 Pipeline 是一个有向无环图,每个节点是一个处理器,每条边由处理器的 InPort 和 OutPort 相连构成,数据到达不同的处理器进行计算后,通过边流向下一个处理器,多个处理器可以并行计算,在集群模式下还可以跨节点分布式执行。
架构与设计 - Storage
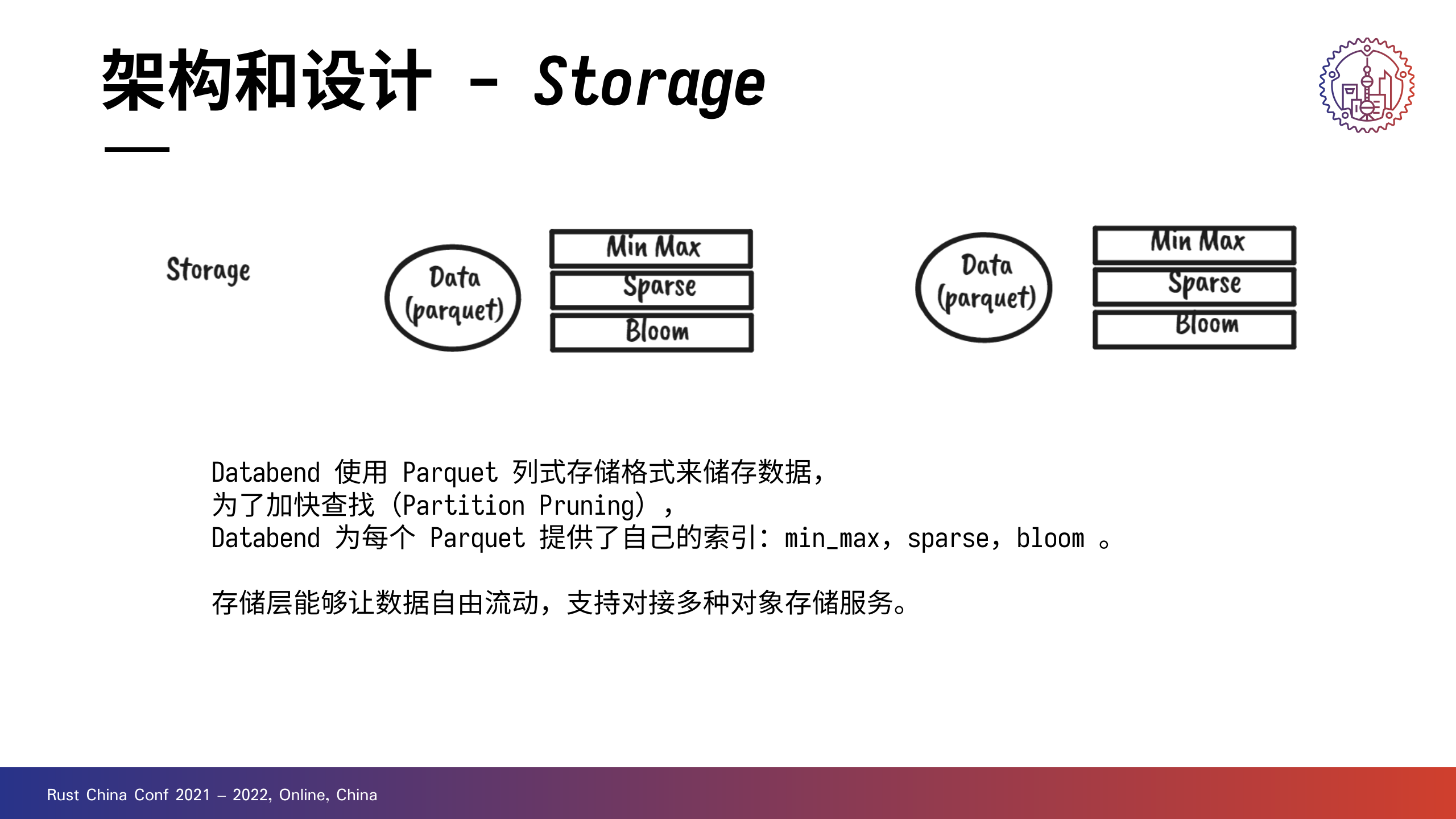
Databend 使用 Parquet 格式储存数据,为了加快查找(Partition Pruning),Databend 为每个 Parquet 提供了自己的索引:min_max,bloom 。这一部分工作是放在存储层完成的。
前面其实有提到,存储层的另一个说法是数据访问层。
一方面,它支持对接多种对象存储服务,像 AWS S3 和 Azure Blob,做到让数据自由流动。当然也支持在本地文件系统做测试,但是没有做专门的性能优化。
另一方面,存储层也支持挂载多种 catalog,在社区小伙伴的帮助下,Databend 完成了 Hive 引擎的对接,支持进行一些简单的查询。
What's New
“存算分离”、“云原生”对于新式数仓而言,只能算是基本特性。除了卯足劲大搞性能优化之外,还有没有其他值得关注的地方呢?让我们一起来看一下。
更加友好的查询体验
好的产品是一定会强调用户体验的,Databend 作为一款云数仓产品,自然要关注查询体验。
那么,在新的 parser 和 planner 中,Databend 引入了语义检查的环节,在查询编译过程中就可以拦截大部分错误。

右图展示的正是两类语义错误,一类是使用了不存在的 Column ,一类是 Column 具有歧义。
全新 Planner
其实新 planner 除了更加友好的查询体验之外,还为支持复杂查询打下了扎实的基础。那么 Databend 现在可以支持多种 Join 和关联子查询,感兴趣的小伙伴可以体验一下。
在引入新 Planner 之后,计算层的架构得到进一步的划分,当一个查询请求进来以后,会经过以下处理:
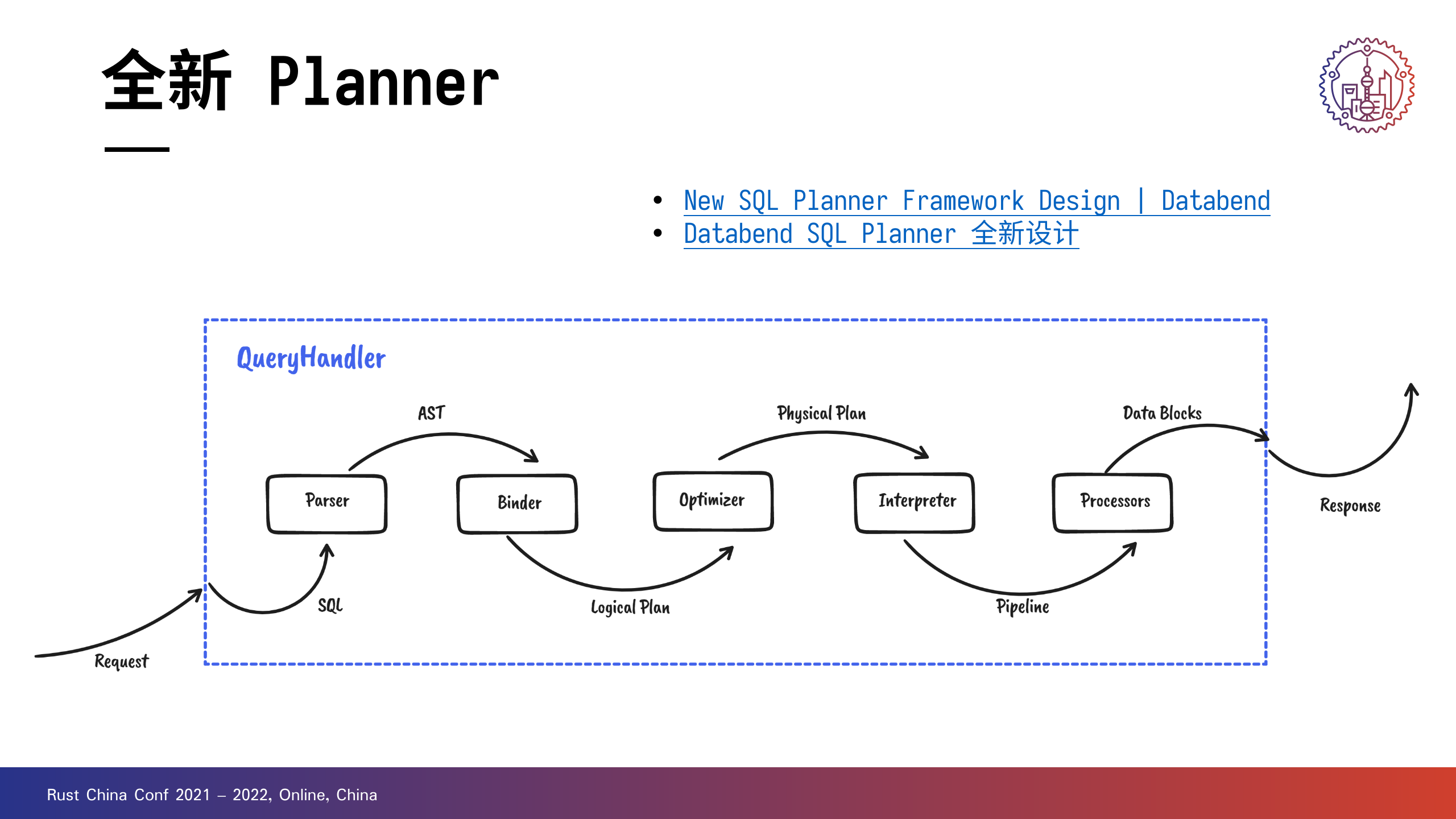
- 基于 nom 定制的解析器会负责生成抽象语法树,值得一提的是,在新 parser 中支持新语句也非常方便。
- Binder 会对语法树进行语义分析,并且生成一个初始的 Logical Plan(逻辑计划)。
- 基于规则的 Cascades 优化器框架会对 Logical Plan 进行改写和优化,最终生成一个可执行的 Physical Plan 。
- Physical Plan 经由解释器翻译成可执行的 Pipeline,并交由 Databend 的 Processor 执行框架进行计算。
- 在处理器执行之后得到一些 data blocks 用于生成最终的查询结果。
对新 plannere 感兴趣的朋友可以看一下下面列出的内容。
类型安全的 Expression
Databend 最近正在研发一套全新的表达式框架,其中包含一套形式化的类型系统,算是使用 Rust 自定义类型系统的最佳范例。

通过引入形式化方法,可以提高设计的可靠性和健壮性。对应到新表达式框架中:
一方面,引入类型检查,可以拦截 SQL 编译阶段的所有类型错误,运行时不再需要关注类型信息。
另一方面,实现了类型安全的向下转型(downcast),得益于 Rust 的类型系统,只要函数能够正常编译就不需要担心类型转换的问题。
当然,性能和开发体验也是新表达式框架非常关心的部分:
通过 Enum 进行静态分发,可以减少运行时开销,降低开发难度。
另外,在函数签名中大量使用泛型,减少手写的重载。
图的右侧给出了一个例子:用几行代码即可定义一个快速、类型安全、自动向下转型并支持向量化的二元函数。
如果对使用 Rust 自定义类型系统感兴趣,可以阅读下面列出的材料。我们也正在积极推进这套表达式框架的开发和迁移工作,欢迎体验。
In Rust Way
作为用 Rust 开发的大型项目,Databend 在一年半的迭代中也积累了一些经验,借这个机会和大家分享一下。
快速迭代
Databend 选择 Rust ,其实有很多原因:极客精神、健壮性等。
团队成员老 C 也分享了他的一个想法:
- 在解决可预期的“编译时间”和难预期的“运行时问题”之间,更应该选择前者。人生苦短,浪费时间在解决运行时的各种内存问题太不值当了。
参见:周刊(第7期):一个C系程序员的Rust初体验 - codedump的网络日志

这里给大家分享一下 Databend 的快速迭代方法论。
- 首先是要及时更新工具链和依赖关系,分享上游的最新成果。
- 利用好 fmt 和 clippy 这些工具,打造适合团队协作的代码风格。
- 作为大型项目,依赖管理其实很重要,要利用好生态中的一些管理和审计工具。
- 比如大家常用的 audit ,可以帮忙审计安全漏洞。
- 另外,也要积极探索一些能够改善开发体验的新工具。
- 比如 nextest,能够在数十秒将几分钟的测试跑完。
- 再比如 goldenfiles 测试,在 similar 的加持下,可以很方便找出预期与实际结果的差异。
测试风格

Databend 的单元测试组织形式有别于一般的 Rust 项目,像上图左侧展示的这样,针对性地禁用了 src 目录下的 doctest 和 test 。
主要的优点就是节省构建测试需要的时间。
一方面,减少遍历和检查的环节,并削减要构建的 test 目标;另一方面,如果不修改 src ,添加新单元测试时只需要编译对应的 test 目标。
当然这样做也有缺点:不利于软件设计上的分层,需要引入编码规范并且更加依赖开发者的主动维护。
上图右侧是 goldenfiles 的一个测试文件片段。Golden Files 测试是一种常用的测试手段,相当于是一类快照测试。我们计划大量使用它来替代手写断言。一方面变更测试文件无需重新编译,另一方面提供自动生成的办法可以减轻写测试的痛苦。
测试相关的一些阅读材料见下:
- Delete Cargo Integration Tests
- Databend 社区如何做测试 [ 虎哥的博客 ] (bohutang.me)
- 如何为 Databend 添加新的测试 | Databend 内幕大揭秘
代码演进
重构要兼顾性能和开发人员的心智负担,这里分享 Databend 代码演进的两个例子。
eg.1

第一个例子是大家编写异步代码时常用的 async trait ,用起来很方便,就像左上角的例子,但是有一些小缺点:
一是动态调度会带来开销,比较难做一些编译器的优化。 二是内存分配也会带来开销,每次调用都需要在堆上新建一个对象。如果是经常调用的函数,就会对程序的性能造成比较大的影响。
那么有没有解决办法呢?左下角的例子中使用泛型关联类型对它进行了改写,虽然避免了开销,但是实现起来还是相对复杂一些。
右上角是使用 SAP 的同学作的 async-trait 分叉,只需要加一个 unboxed_simple 就可以做到同样的效果,省心省力。
- Skyzh | 2022-01-31-gat-async-trait/
- Allow 'async fns' to return 'impl Future'
- wvwwvwwv‘s async-trait fork with unboxed
eg.2

第二个例子是关于分发的,分发其实就是要确定调用接口时是调用哪个实例和它具体的类型。分发的方式不同,其成本也不同。
左上角的例子是利用 trait object 动态分发,当然这会有一些开销。
左下角使用 enum 进行静态分发,从语法上更便利。有数十倍的一个提升,但是 enum-dispatch 实现上比较硬核,基本上无法自动展开,需要自己手写规则。
在新表达式框架中,使用 EnumAsInner 完成静态分发,代码更简洁,而且对 IDE 也更友好。
踩坑小记
尽管 Rust 是一门健壮的语言,但程序的健壮性还需要开发者自己用心,这里分享两例完全可以避免的内存问题。
eg.1

之前,上图中的代码片段没有加环境变量判断,导致程序会默认开启日志发送服务。
但可能这个时候集群里没开对应的日志收集服务,没发的日志被 buffer 住,时间久了越攒越多,自然引发 OOM 。
eg.2
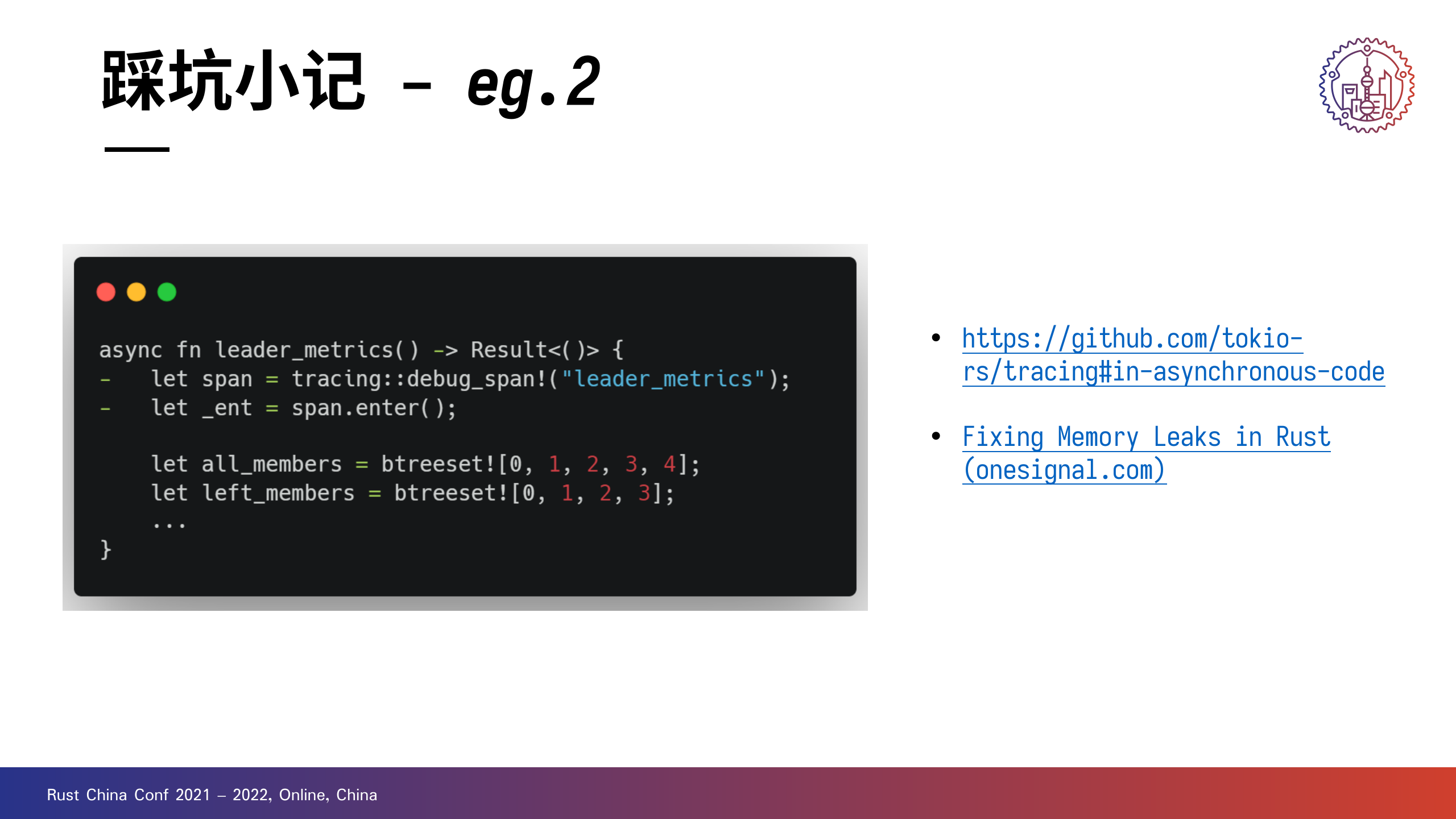
左图这个代码片段其实 tracing 的文档中已经给了提示。
由于进入的 span 在异步执行结束后无法正确释放,会造成内存。onesignal 为此专门写了一篇文章,比较值得读。
- https://github.com/tokio-rs/tracing#in-asynchronous-code
- Fixing Memory Leaks in Rust (onesignal.com)
社区
Databend 的成长离不开 Rust 社区和开源共同体,Databend 社区也在为共筑更好的 Rust 生态而努力。
开源项目
这里介绍三个 Databend 社区维护的开源项目。
openraft
-
https://github.com/datafuselabs/openraft
openraft 是基于 tokio 运行时的异步共识算法实现,是披着 Raft 外壳的 Paxos,旨在成为构建下一代分布式系统的基石。
目前已经应用在 SAP / Azure 的项目中。
opendal
-
https://github.com/datafuselabs/opendal
opendal 的口号是:让所有人都可以无痛、高效地访问不同存储服务。
近期的提案包括实现一个命令行工具,以操作不同服务中存储的数据,并支持数据迁移。
opensrv
-
https://github.com/datafuselabs/opensrv
opensrv 为数据库项目提供高性能和高可度可靠的服务端协议兼容,建立在 tokio 运行时上的异步实现。目前在 CeresDB 中得到应用。
课程
自 21 年 8 月起,Databend 和 Rust 中文社区、知数堂, 启动了面向 Rust 和数据库开发人员的公开课计划,前后一共输出 34 期课程。
新一轮的公开课也在积极筹备,敬请期待。
上游优先
对待开源,Databend 一直秉承着上游优先的理念。也就是说开源协作理所当然地需要将变更反馈给社区。不光是做一个好的用户,也要做一个好的开发者。
一个典型的例子是 arrow2 ,Databend 的核心依赖,我们应该是最早一批使用 arrow2 的项目。在 arrow2 的贡献者中有 9 位是 Databend Labs 成员,其中有三位是 top 15 贡献者。
Databend Cloud
Databend 是一款云数仓,不仅仅是云原生数仓,更是云上数仓。
一站式数据分析云平台

Databend Cloud 是 Databend 打造的一款易用、低成本、高性能的新一代大数据分析平台,让用户更加专注数据价值的挖掘。
目前 Databend Cloud 正处于测试阶段,有需要的朋友可以访问 app.databend.com 注册帐号体验。