查询执行
查询在数据库系统中的调度与执行方式同样会深刻影响到数据库的性能表现。本文简要梳理了查询流程中与执行相关的内容,希望能够帮助大家更好理解查询引擎的工作原理。
查询的基本流程
首先一起来回顾一下查询的基本流程。
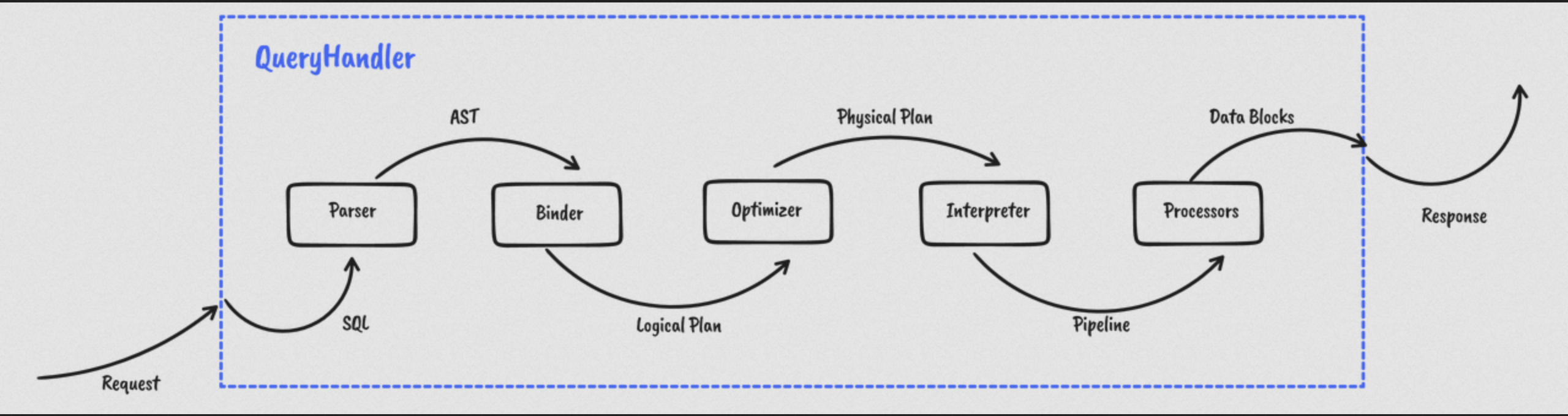
如上图所示,查询往往需要经历下述几个阶段:
- 解析 SQL 语法,形成 AST(抽象语法树)。
- 通过 Binder 对其进行语义分析,并且生成一个初始的 Logical Plan(逻辑计划)。
- 得到初始的 Logical Plan 后,优化器会对其进行改写和优化,最终生成一个可执行的 Physical Plan 。
- 通过 Optimizer 生成 Physical Plan 后,将其翻译成可执行的 Pipeline 。
- Pipeline 则会交由 Processor 执行框架进行计算。
从 Volcano Model 开始
1990 年发表的 Volcano, an Extensible and Parallel Query Evaluation System 中提出 Volcano Model 并为人熟知。

Volcano 是一种基于行的流式迭代模型,简单而又优美。拉取数据的控制命令从最上层的算符依次传递到执行树的最下层,与数据的流动方向正好相反。
优点
- 对 Data Stream 进行抽象并提供一系列标准接口,各个算符之间充分解耦。模型简单,易于扩展。
- 框架完成了算符组合和数据处理的整体流程,算符的实现只要关注数据的处理流程。与执行策略隔离,具有很强的灵活性。
缺点
- 采用 Pull 模型拉取数据,数据在算符之间的流动需要额外的控制操作,所以存在大量冗余的控制指令。
- 迭代器模型意味着算符之间需要大量
next()调用,虚函数嵌套对分支预测并不友好,会破坏 CPU 流水线并造成 Cache 和 TLB 失效。
小结
时至今日,内存容量突飞猛进,数据可以直接存放在内存中,负载从 IO bound 转向 memory bound ;而 CPU 单核效率面临瓶颈,多核能力日益重要,更需要关注 CPU 执行效率。向量化执行/编译执行等方式开始绽放异彩。
尽管 Volcano Model 受限于当时尚未成熟的硬件环境(CPU 并行能力不足、内存容量小且 IO 效率低下),但它的设计仍然值得借鉴,在现代一些 state of the art 执行器方案中,仍然可以看到它的影子。
迈向 Morsel-Driven Parallelism
Databend 的执行器部分主要借鉴了 Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age 这篇论文。

面向多核架构
Morsel 有「小块」的意思,意味着任务会被拆解成大小合适、可动态调整的一系列算子,比如表达式的计算、聚合函数的计算等。而 Morsel-Driven Parallelism 提供了一种自适应的调度执行方案,在运行时确定任务的并行度,按流水线的方式执行操作,并通过调度策略来尽量保证数据的本地化,在实现 load balance 的同时最小化跨域数据访问。
合理分发任务
汽车的流水线生产需要各个部门、各种零件配合,查询的高效执行也离不开不同算子的组合。
这时就需要引入一个调度器(Dispatcher)为并行的 Pipeline 控制分配计算资源。Dispatcher 维护着各个查询传递而来的 Pipeline Jobs,每个任务都相当于查询的一个子计划,会对应到底层需要处理的数据。在线程池请求分发 Task 时,Dispatcher 会遵循调度策略,根据任务执行状态、资源使用情况等要素,来决定什么时候 CPU 该执行哪个 Transform 。
Morsel Wise
Morsel-Driven Parallelism 的研究不仅仅关注执行框架的改进,还涵盖一些特定算法的并行优化,比如 Hash Join、Grouping/Aggregation 以及排序。
在 Morsel Wise 思想的指导下,Morsel-Driven Parallelism 执行框架解决了多核时代中负载均衡、线程同步、本地内存访问以及资源弹性调度的问题。
再谈列式存储与向量化执行
向量化执行自 MonetDB/X100(Vectorwise)开始流行,MonetDB/X100: Hyper-Pipelining Query Execution 这篇论文也成为了必读之作。而在 2010 年之后的 OLAP 系统,基本上都是按列式存储进行数据组织的。
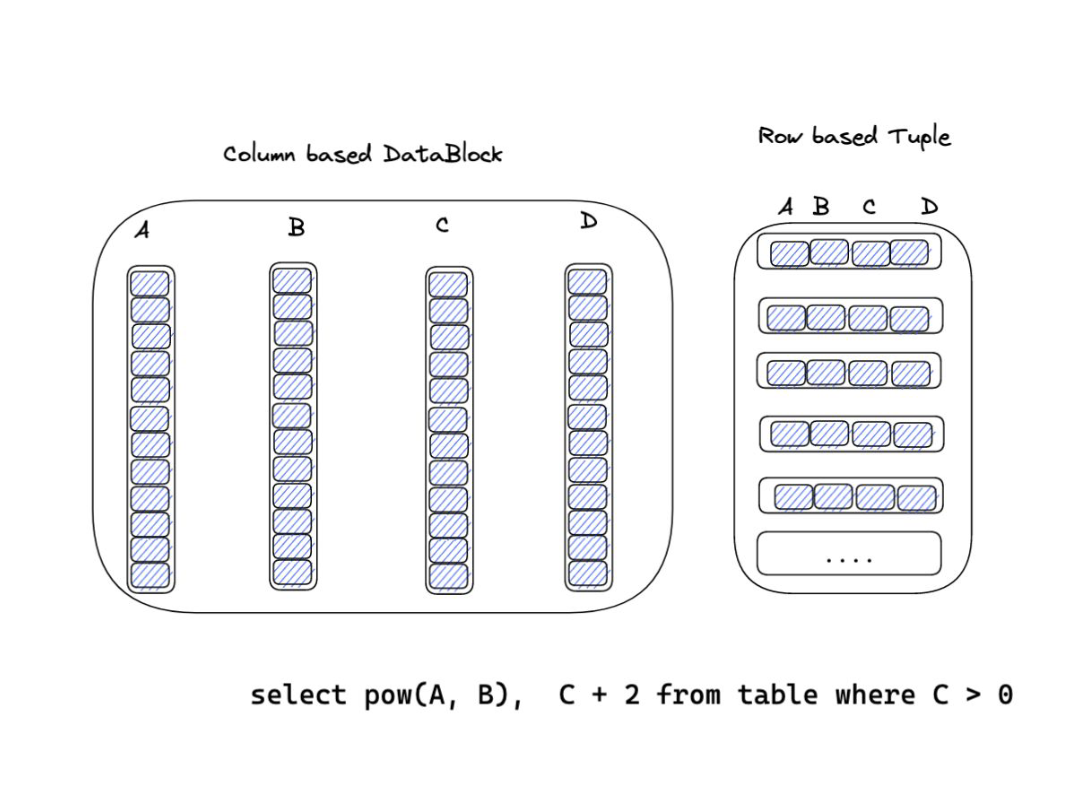
列式存储
OLAP 系统需要处理的查询通常涉及大量的数据,采用列式存储方案在提高 IO 效率方面具备天然优势。
- 只需要读取需要的列,无需经 IO 读取其余列,从而避免不必要的 IO 开销。
- 同一列的数据中往往存在大量的重复项,压缩率会非常高,进一步节约 IO 资源。
向量化执行
向量化执行的优势在于可以充分利用 CPU 缓存,从而设计更为高效的分析查询引擎。
- 数据在内存中连续;由于做到按需读取,还能减少不必要的缓存占用。
- 减少处理数据时需要传递的数据量,并摊匀不同算符之间调用的开销。
SIMD 优化
谈到向量化执行,不可避免要用到 SIMD(单指令多数据)。传统的方式是查询指令集,然后手工编写指令;而在 Databend 中,采用以下方式:
- 利用 Rust 语言标准库,
std::simd提供关于 SIMD 指令的抽象封装,可以编写易于理解的代码。 - 自动向量化,通过优化代码逻辑,削减循环中的分支预测,充分利用编译器的能力。
关于 Databend 查询执行的一些问答
以下内容整理自 @fkuner 和 @zhang2014 的一次对话。
-
Databend 中如何保证 numa-local ?
答:numa-local 在 aggregator processor 中是 core 独享的。pipelines size 和 executor worker size 1:1 对应也是为了numa local 。在调度时,尽量不会切换线程。一个任务从头调度到尾,将新产生的支线任务放入全局调度。
-
Pipeline 如果需要等待 IO 是如何调度的?
答:Databend 通过感知数据状态来调度 Pipeline,如果数据没有准备好不会调度。至于 IO ,会被调度到 global io runtime 中,通过 Rust Async 阻塞等待。
-
任务、Pipeline 和 Processor 的对应关系是怎样的?
答:论文中的模型是:一个任务处理一个 Pipline ,而一个 Pipeline 可以由多个 Processor 组成。而 Databend 可以在 Processor 级别做任务窃取,任务切割到 Processor 级别可切分的情况下,调度是更灵活的。虽然是在调度器中调度Processor,但这个 Processor 在运行状态中具体对应到的就是一个 Data Block 。类似论文中 Pipeline 的 Job 切分。
-
Databend 中对 numa-local 倾向性的调度处理是如何做的?
答:理想状态下执行线程应该互不干扰,但考虑到任务可能存在倾斜。当其中某个线程提前完成任务时,为了加速整个执行流程可能需要该线程窃取剩下的任务。在调度时,执行器会存在一个 local context ,不会在线程间存在任何共享。