多云转晴:Databend 的天空计算之路
本文介绍了天空计算的概念和背景,以及 Databend 的跨云数据存储和访问。欢迎部署 Databend 或者访问 Databend Cloud ,即刻探索天空计算的无尽魅力。

背景
云计算时代的开端可以追溯到 2006 年,当时 AWS 开始提供 S3 和 EC2 服务。2013 年,云原生概念刚刚被提出,甚至还没有一个完整的愿景。时间来到 2015 年 CNCF 成立,接下来的五年中,这一概念变得越来越流行,并且成为技术人绕不开的话题。
根据 CNCF 对云原生的定义:云原生技术使组织能够在公共、私有和混合云这类现代、动态的环境中构建和运行可扩展的应用程序。典型示例包括:容器、服务网格、微服务、不变基础设施和声明式 API 。

然而,无论是公有云还是私有云、无论是云计算还是云服务,在天空中都已经存在太多不同类型的“云”。每个“云”都拥有自己独特的 API 和生态系统,并且彼此之间缺乏互操作性,能够兼容的地方也是寥寥无几。云已经成为事实上的孤岛。这个孤岛不仅仅是指公有云和私有云之间的隔阂,还包括了不同公有云之间、不同私有云之间、以及公有云和私有云之间的隔阂。这种孤岛现象不仅给用户带来了很多麻烦,也限制了云计算的发展。
2021 年 RISELab 发表了题为 The Sky Above The Clouds 的论文,讨论关于天空计算的未来。天空计算将云原生的思想进一步扩展,从而囊括公有云、私有云和边缘设备。其目标是实现一种统一的 API 和生态体系,使得不同云之间可以无缝地协作和交互。这样一来,用户就可以在不同的云之间自由地迁移应用程序和数据,而不必担心兼容性和迁移成本的问题。同时,天空计算还可以提供更高效、更安全、更可靠的计算服务,从而满足用户对于云计算的不断增长的需求。总体上讲,天空计算致力于允许应用跨多个云厂商运行,实现多云之间的互操作性。

(上图引自论文,展示不同类型的多云与天空的区别)
The Databend Way
跨云的关键
Databend 能够满足用户在不同的云之间自由地访问数据并进行查询,而不必担心兼容性和迁移成本的问题。同时,Databend 还可以提供更高效、更安全、更可靠的计算服务,从而满足用户对于云计算的不断增长的需求。从这个角度来看,Databend 已经初步形成了一套天空计算的解决方案。那么,对 Databend 而言,跨云的关键到底落在哪里呢?
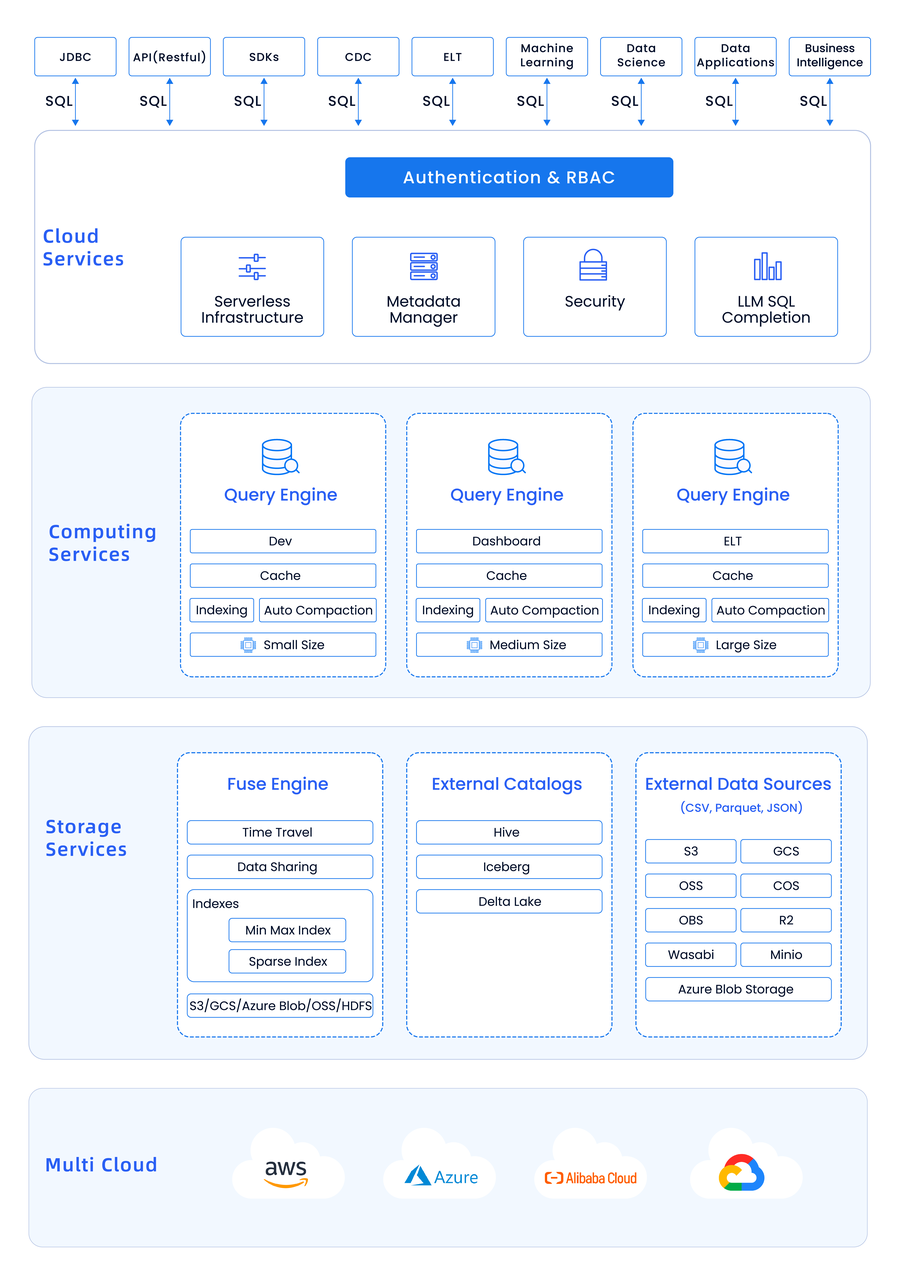
(上图所示为 Databend Cloud 架构示意图)
Databend 采用存算分离的架构,并完全面向云对象存储进行设计决策。得益于存储与计算分离、存储与状态分离,Databend 可以实现对资源的精细化控制,轻松部署与扩展 Query 和 Meta 节点 ,并支持多种不同的计算场景和存储场景,而无需考虑跨云数据管理与移动的问题。
Query 节点和 Meta 节点本身都是轻量化的服务,并且对于部署环境没有严格的依赖。但数据的存储和访问管理就不一样,我们需要考虑不同云服务之间的 API 兼容性、以及如何与云服务本身的安全机制交互从而提供更安全的访问控制机制。对于 Databend 而言,跨云,或者说实现天空计算的关键,就落在数据的管理与访问之上。
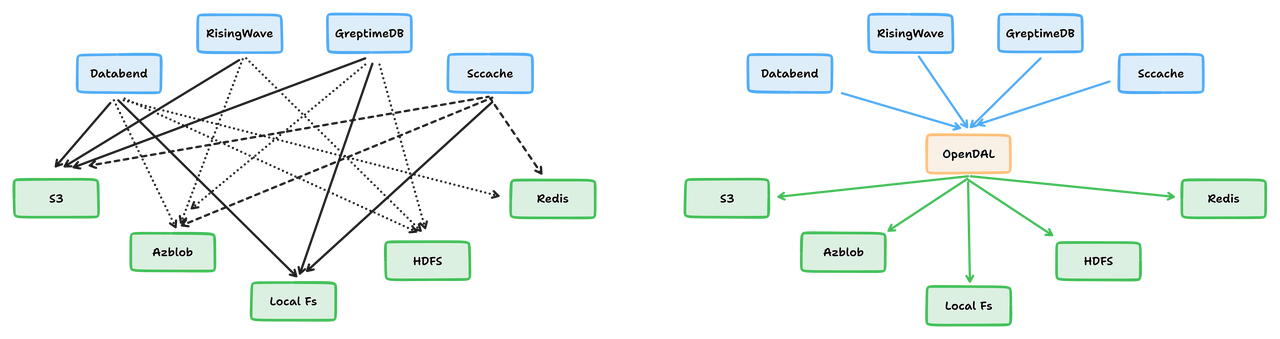
(OpenDAL 可以将数据访问问题从 M*N 转化为 M+N)
为了解决这一问题,Databend 抽象出一套统一的数据访问层(OpenDAL,现在是 Apache 软件基金会旗下的孵化项目),从而屏蔽了不同云服务之间的 API 兼容性问题。在接下来的部分,我们将会从不同的视角来观察 Databend 的无痛数据访问体验,体验真正完全云原生的天空计算的魅力。
数据存储
Databend 存储后端的细节隐藏在简单的配置之下,通过修改配置文件就可以轻松地在十数种存储服务之间切换。例如,如果你想使用 AWS S3,只需要指定类型为 s3 即可,Databend 会自动尝试使用 IAM 来进行认证。如果你想使用其他与 S3 兼容的对象存储服务,也可以通过 endpoint_url 等设置来调整。
[storage]
type = "s3"
[storage.s3]
bucket = "databend"
当然,仅支持 S3 兼容的对象存储服务还不够。Databend 通过 OpenDAL 实现了 Google Cloud Storage、Azure Blob、Aliyun OSS、Huawei OBS 和 HDFS 等服务的原生存储后端支持。 这意味着 Databend 可以充分利用各种供应商提供的 API,为用户带来更优秀的体验。例如,Aliyun OSS 的原生支持使得 Databend 可以通过 Aliyun RAM 对用户进行认证和授权,无需设置静态密钥,从而大大提高安全性并降低运维负担。
(上图选自阿里云官网,访问控制场景与能力)
此外,原生支持还可以避免出现非预期行为,并与服务供应商提供更紧密的集成。虽然各大厂商都提供了 S3 兼容 API,但它们之间存在微妙差异,在出现非预期行为时可能会导致服务性能下降或读写数据功能异常。Google Cloud Storage 提供了 S3 兼容的 XML API,但却没有支持批量删除对象的功能。这导致用户在调用该接口时遇到意外错误。而 Google Cloud Storage 的原生支持使 Databend 不必担心 GCS 对 S3 的兼容实现问题对用户业务造成影响。
总之,Databend 通过为各个服务实现原生支持来为用户提供高效可靠的数据分析服务。
数据管理
前面讲过了存储后端的跨云支持,现在让我们将目光聚焦到数据的管理。更具体来说,数据在 Databend 工作流中的流入与流出。
COPY INTO,数据载入
要讲数据管理,就不得不讨论数据从哪里来。过去可能还需要考虑是否需要迁移存储服务,但现在,你可以从数十种 Databend 支持或兼容的存储服务中加载数据,一切都显得那么自然。
COPY INTO 语句是窥探 Databend 跨云能力的一个窗口,下面的示例展示了如何从 Azure Blob 加载数据到 Databend 之中。
COPY INTO mytable
FROM 'azblob://mybucket/data.csv'
CONNECTION = (
ENDPOINT_URL = 'https://<account_name>.blob.core.windows.net'
ACCOUNT_NAME = '<account_name>'
ACCOUNT_KEY = '<account_key>'
)
FILE_FORMAT = (type = CSV);
当然,不止是 Azure Blob ,Databend 支持的其他云对象存储服务、IPFS 以及可以经由 HTTPS 访问的文件都可以作为 External location ,通过 COPY INTO 语句加载进来。
Databend 的
COPY INTO语句还支持进行基本的转换服务,可以减轻 ETL 工作的负担。
Stage ,数据暂存区
刚刚提到 External location ,事实上,要加载到 Databend 中的数据文件还可以在 Stage 中暂存。Databend 同样支持 Internal stage 和 Named external stage 。
数据文件可以经由 PUT_INTO_STAGE API 上传到 Internal Stage,由 Databend 交付当前配置的存储后端进行统一管理。而 Named external stage 则可以用于挂载其他 Databend 支持的多种存储服务之中的 bucket 。
下面的例子展示了如何在 Databend 中创建一个名为 whdfs 的 Stage ,通过 WebHDFS 协议将 HDFS 中 data-files 目录下的数据文件导入 Databend 。
bendsql> CREATE STAGE IF NOT EXISTS whdfs URL='webhdfs://127.0.0.1:9870/data-files/' CONNECTION=(HTTPS='false');
Query OK, 0 rows affected (0.01 sec)
bendsql> COPY INTO books FROM @whdfs FILES=('books.csv') file_format=(type=CSV field_delimiter=',' record_delimiter='\n' skip_header=0);
Query OK, 2 rows affected (1.83 sec)
如果你并不想直接导入数据,也可以尝试
SELECT FROM STAGE,快速分析位于暂存区中的数据文件。
Catalog,数据挂载
放在对象存储中的数据加载得到了解决,还有一个值得思考的问题是,如果数据原本由其他数据分析系统所管理,该怎么办?
Databend 提供多源数据目录(Multiple Catalog)的支持,允许挂载 Hive 、Iceberg 等外部数据目录。
下面的示例展示如何利用配置文件挂载 Hive 数据目录。
[catalogs.hive]
type = "hive"
# hive metastore address, such as 127.0.0.1:9083
address = "<hive-metastore-address>"
除了挂载,查询也是小菜一碟 select * from hive.$db.$table limit 10; 。
当然,这一切也可以通过 CREATE CATALOG 语句轻松搞定,下面的例子展示了如何挂载 Iceberg 数据目录。
CREATE CATALOG iceberg_ctl
TYPE=ICEBERG
CONNECTION=(
URL="s3://my_bucket/path/to/db"
AWS_KEY_ID="<access-key>"
AWS_SECRET_KEY="<secret_key>"
SESSION_TOKEN="<session_token>"
);
Multiple Catalog 相关的能力还在积极开发迭代中,感兴趣的话可以保持关注。
再探 COPY INTO,数据导出
数据导出是数据管理中的另外一个重要话题,简单来讲,就是转储查询结果以供进一步的分析和处理。
这一能力同样由 COPY INTO 语法提供支持,当然,同样支持数十种存储服务和多种文件输出格式。下面的示例展示了如何将查询结果以 CSV 格式文件的形式导出到指定 Stage 中。
-- Unload the data from a query into a CSV file on the stage
COPY INTO @s2 FROM (SELECT name, age, id FROM test_table LIMIT 100) FILE_FORMAT = (TYPE = CSV);
这一语法同样支持导出到 External location ,真正做到数据的自由流动。
Databend 还支持
PRESIGN,用来为 Stage 中的文件生成预签名的 URL ,用户可以通过 Web 浏览器或 API 请求自由访问该文件。
数据共享
刚才提到的 Databend 数据管理环节跨云主要是指 Databend 与外部服务之间的交互。此外,Databend 实例之间也可以经由多种云存储服务来支持数据共享。
为了更好地满足多云环境下的数据库查询需求,Databend 设计并实现了一套 RESTful API 来支持数据共享。
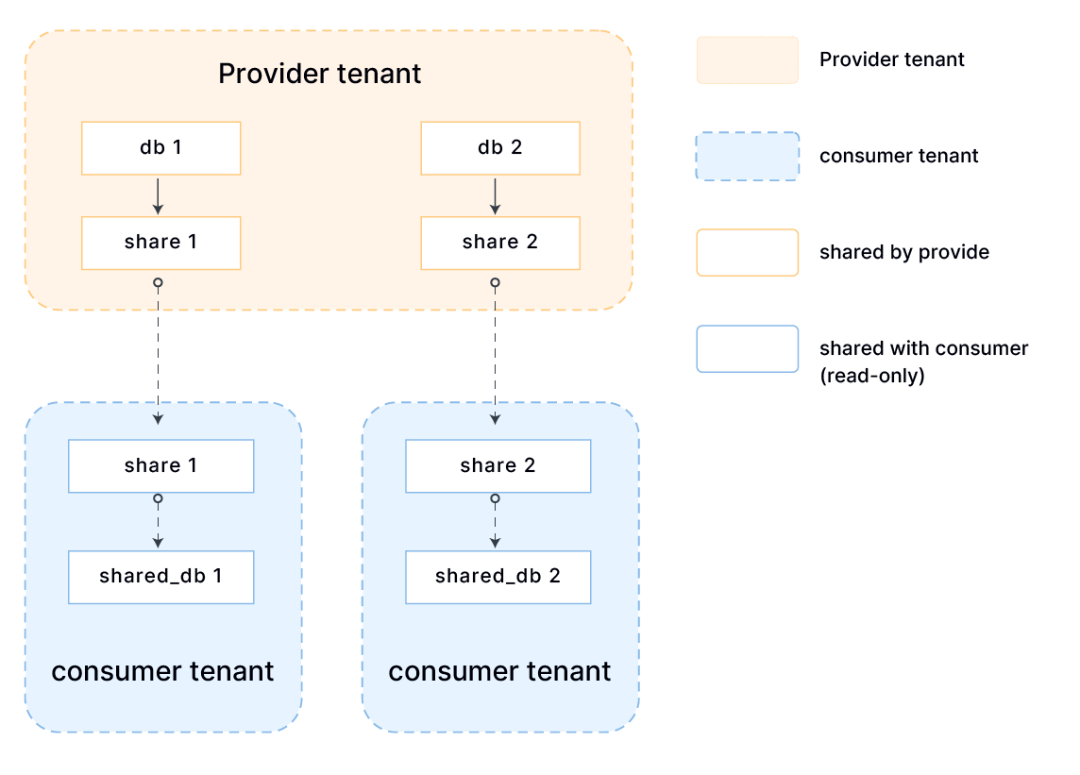
(上图所示为数据共享的工作流)
通过在配置文件中添加 share_endpoint_address 相关配置,用户可以利用预先部署好的 open-sharing 服务,经由熟悉的云存储服务共享 Databend 管理的数据库或表。
CREATE SHARE myshare;
GRANT USAGE ON DATABASE db1 TO SHARE myshare;
GRANT SELECT ON TABLE db1.table1 TO SHARE myshare;
ALTER SHARE myshare ADD TENANTS = vendor;
此时,表 db1.table1 将对接受方租户 vendor 可见,并能够进行必要的查询。
CREATE DATABASE db2 FROM SHARE myshare;
SELECT * FROM db2.table1;
跨云的未来
上面的几个视角,只是展示 Databend 在天空计算道路上的一个小小侧影。
数据合规、隐私保护等内容同样是我们所关心的重要议题。
Databend 的愿景是成为未来跨云分析的基石,让数据分析变得更加简单、快速、便捷和智能。
总结
本文介绍了天空计算的概念和背景,以及 Databend 的跨云数据存储和访问。
天空计算是一种将公有云、私有云和边缘设备统一起来的方法,目标是提供一种无缝的 API 和生态体系,使得用户可以在不同的云之间自由地迁移应用程序和数据。
Databend 是一个开源的、完全面向云架构的新式数仓,它采用存算分离的架构,并抽象出一套统一的数据访问层(OpenDAL),从而屏蔽了不同云服务之间的 API 兼容性问题。Databend 可以满足用户在不同的云之间自由地访问数据并进行查询,而不必担心兼容性和迁移成本的问题。同时,Databend 还可以提供更高效、更安全、更可靠的计算服务,从而满足用户对于云计算的不断增长的需求。
欢迎部署 Databend 或者访问 Databend Cloud ,即刻探索天空计算的无尽魅力。