Databend 源码阅读: 图解 pipeline 调度模型
作者:JackTan25 | Databend Contributor
一.基于图的初始化
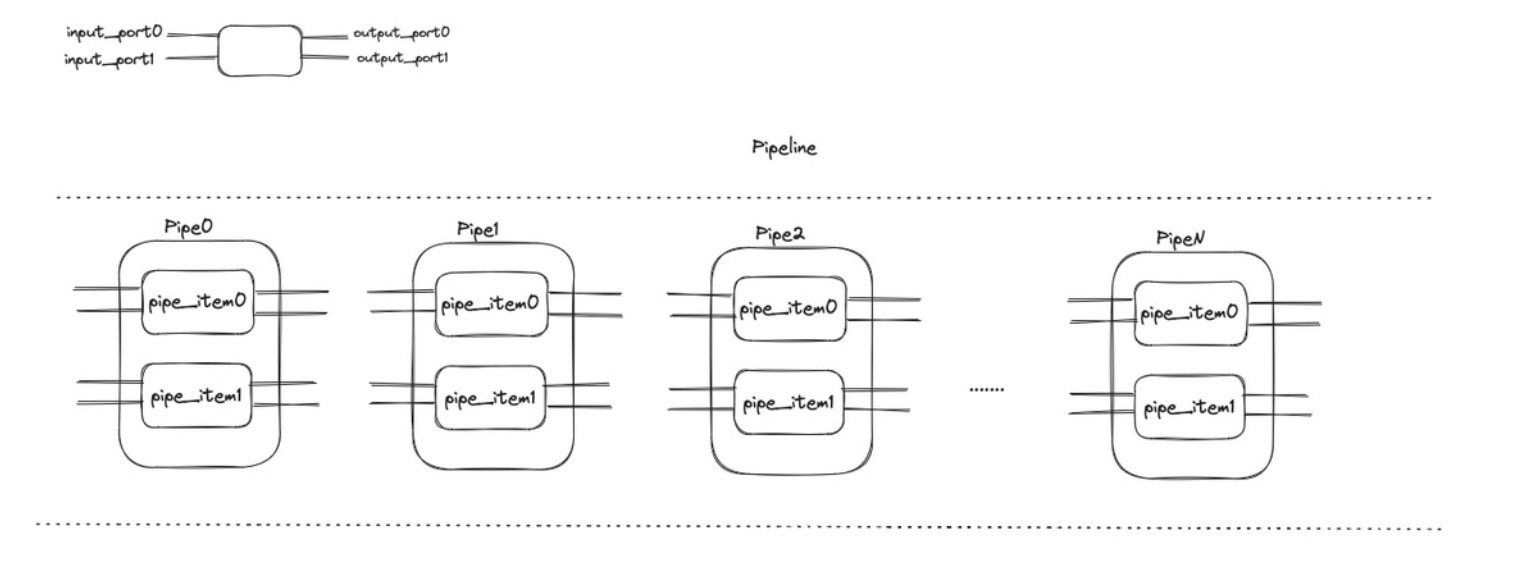
上图便是 databend 的一条 pipeline 结构,通常对于每一个 PipeItem,这里只会有一个 input_port 和 output_port,一个 Pipe 当中的 PipeItem 的数量则通常代表着并行度.每一个 PipeItem 里面对应着一个算子(不过在有些情况下并不一定一个 pipeItem 就只有一对 input_port 和 output_port,所以上图画的更加广泛一些),算子的推进由调度模型来触发
将 pipeline 初始化为 graph:这里细致展示下生成的过程
databend 采取的是采取的是 StableGraph 这个结构,我们最开始是得到了下面第一张图这样的 Pipeline,我们最后生成的是下面第二张图的 graph.
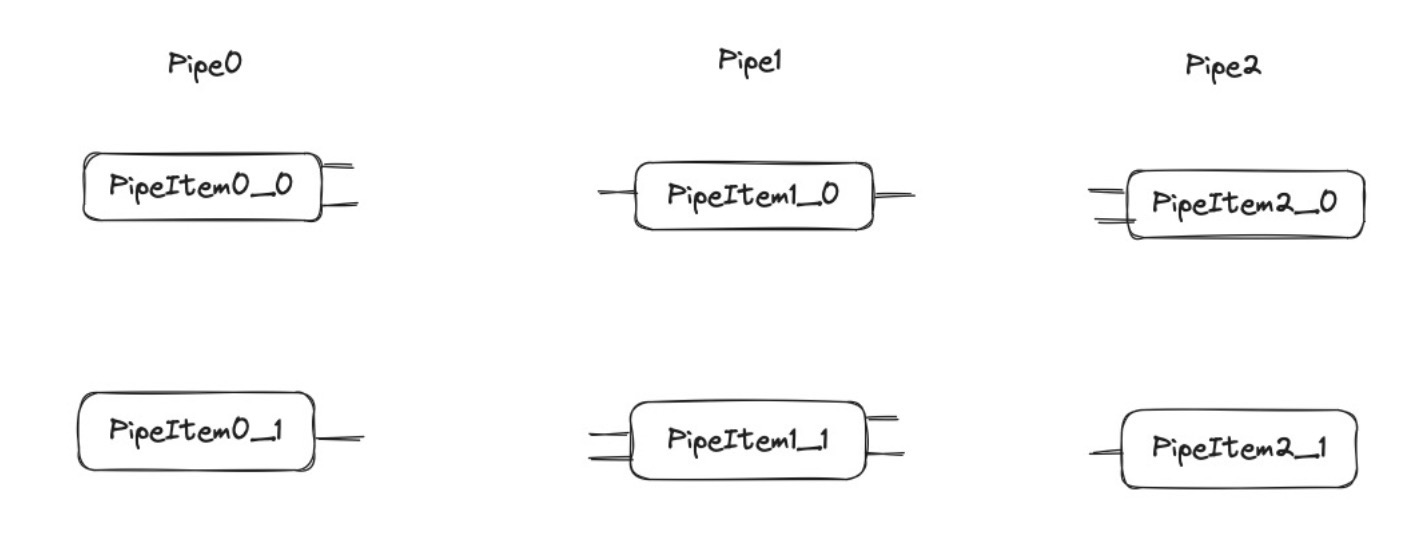
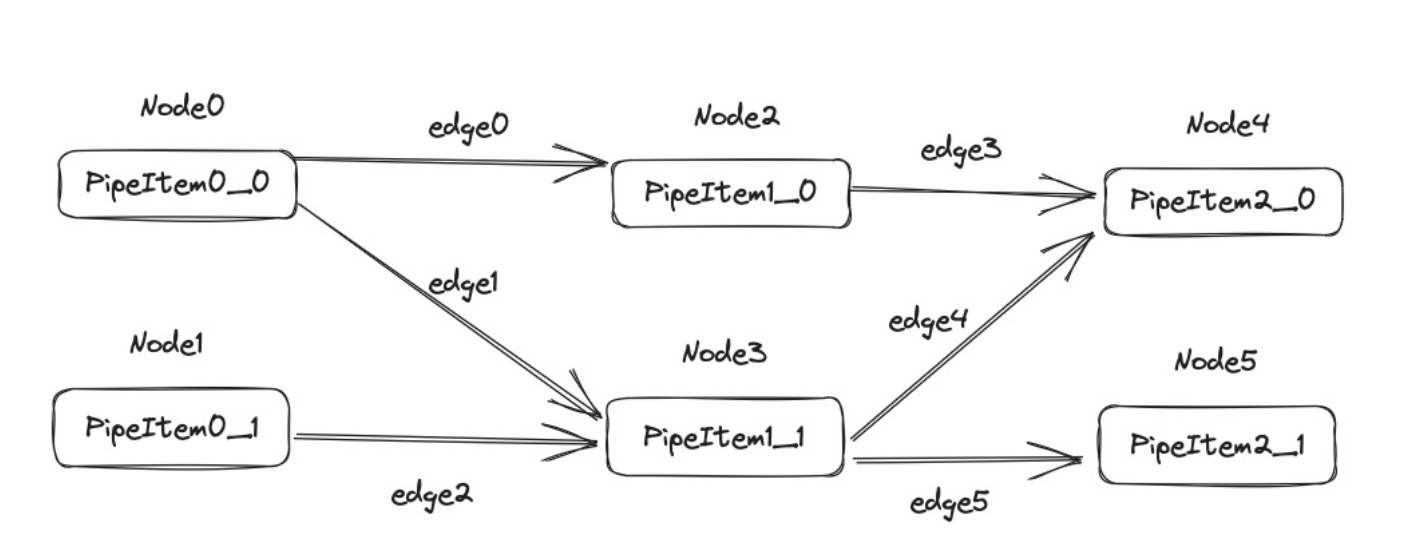
上面第二张图的的连接只是一个物理上的单纯图的连接,但是 node 内部 pipe_item 对应的 port 没有对接起来.我们还需要关心的是具体如何把对应的 port 给连接起来的.在构建图的时候每一个 PipeItem 包装为一个 node,包装的过程是以 Pipe 为顺序的.这样我们就为上面每一个 PipeItem 都加上了一个 Node 编号,后面我们需要按照为对应的 input_port 和 output_port 去加上 edge,我们的连接是一个平行的连接.
我们将构建过程当中需要使用到的结构做一个介绍:
// 一个Node对应一个PipeItem
struct Node {
// node的状态记录,其实应该理解为是记录
// pipeline执行过程当中一个最小执行
// 单元PipeItem的状态,一共有如下三种状态:
// Idle,Processing,Finished,
state: std::sync::Mutex<State>,
updated_list: Arc<UpdateList>,
// 以下是pipeItem的内容
inputs_port: Vec<Arc<InputPort>>,
outputs_port: Vec<Arc<OutputPort>>,
processor: ProcessorPtr,
}
pub struct UpdateList {
inner: UnsafeCell<UpdateListMutable>,
}
pub struct UpdateListMutable {
// update_input与update_output调用时更新,用于
// 调度模型的任务调度
updated_edges: Vec<DirectedEdge>,
// 对于Node而言,其上的每一个input_port和output_port都会对应
// 一个trigger,我们从edge0,edge1,...,edgen(编号就是上图示例)
// 这样每次给source_node为其对应的output_port添加一个trigger
// 为target_node的input_port添加一个trigger
updated_triggers: Vec<Arc<UnsafeCell<UpdateTrigger>>>,
}
// 用于判断调度前驱node还是后驱node
pub enum DirectedEdge {
Source(EdgeIndex),
Target(EdgeIndex),
}
// trigger的作用就是用来后面调度模型推进pipeline向下
// 执行调度任务使用的
pub struct UpdateTrigger {
// 记录该trigger对应的是哪一个边
index: EdgeIndex,
// 记录其属于哪一个UpdateListMutable
update_list: *mut UpdateListMutable,
// 初始化为0
version: usize,
// 初始化为0
prev_version: usize,
}
// 上面的例子最后我们得到的graph初始化后应该是下面这样

// 而对于input_port和output_port的数据的传递,则是两者之间共享一个SharedData
pub struct SharedStatus {
// SharedData按照8字节对齐,所以其地址
// 最后三位永远为0,在这里我们会利用这三
// 位来标记当前port的状态,一共有三种
// NEED_DATA,HAS_DATA,IS_FINISHED
data: AtomicPtr<SharedData>,
}
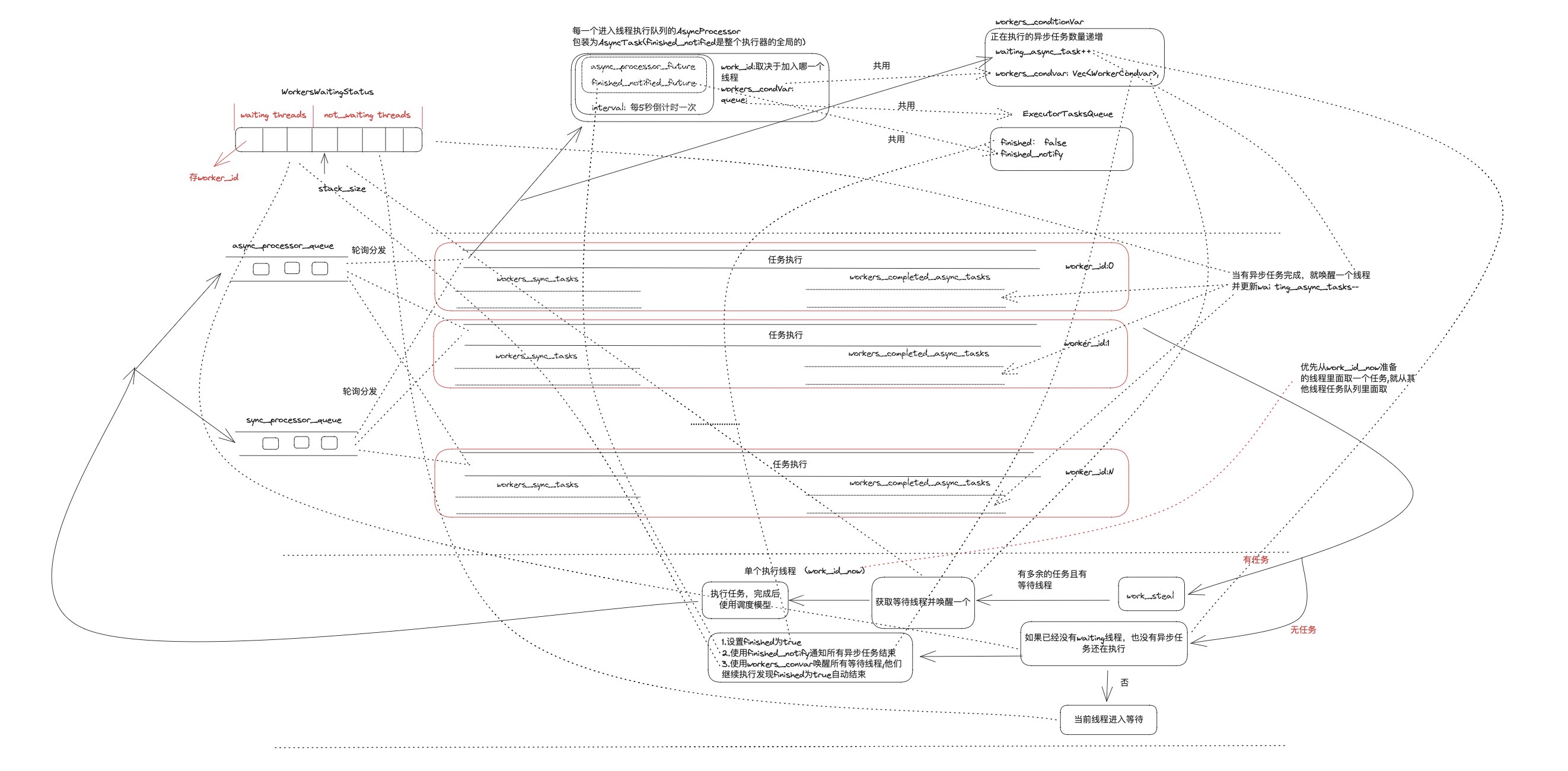
二.基于 work-steal 与状态机的并发调度模型
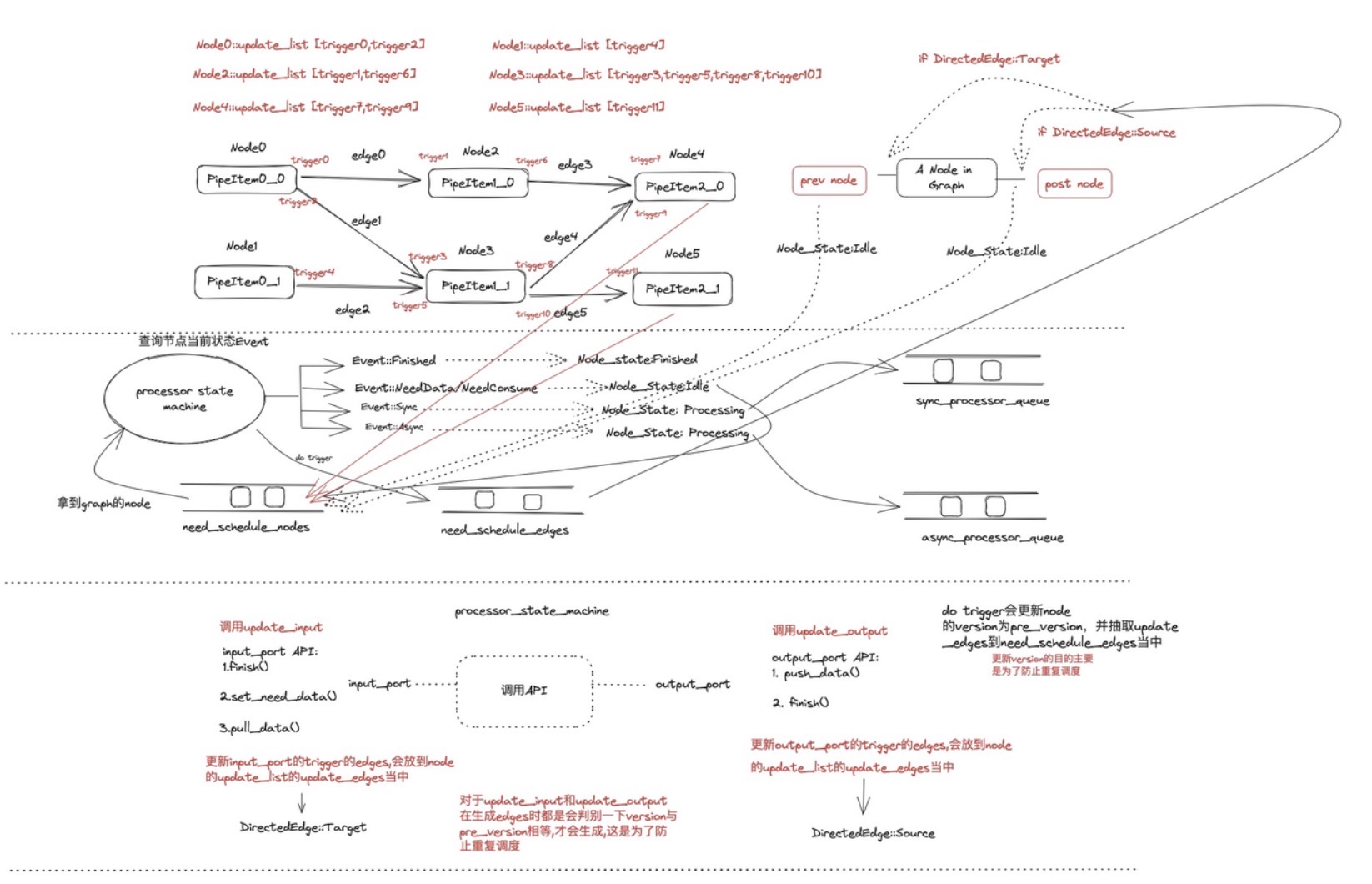
初始化调度是将我们的 graph 的所有出度为 0 的 Node 作为第一次任务调度节点,对应我们的例子就是 Node4,Node5。 每一次调度都是抽取出 graph 当中的同步任务和异步任务,下图是 pipeline 的调度模型,用于抽取出当前 graph 当中可执行的同步 processor 和异步 processor,调度模型的输入是最上面的 graph,而输出则是 sync_processor_queue 和 async_processor_queue,无论是在初始化时还是在后面继续执行的过程都是利用的下面的调度模型来进行调度。 调度模型的执行终点是 need_schedule_nodes 和 need_schedule_edges 均为空。
三.执行模型
执行模型对应相关结构如下:
struct ExecutorTasks {
// 记录当前还剩余的task的数量
tasks_size: usize,
workers_waiting_status: WorkersWaitingStatus,
// 记录同步任务,其大小等于系统当前允许的thread数量
workers_sync_tasks: Vec<VecDeque<ProcessorPtr>>,
// 记录已完成的异步任务,其大小等于系统当前允许的thread数量
workers_completed_async_tasks: Vec<VecDeque<CompletedAsyncTask>>,
}
// 用于记录等待线程和活跃线程
pub struct WorkersWaitingStatus {
stack: Vec<usize>,
stack_size: usize,
worker_pos_in_stack: Vec<usize>,
}
pub struct WorkersCondvar {
// 记录还未执行完的异步任务
waiting_async_task: AtomicUsize,
// 用于唤醒机制
workers_condvar: Vec<WorkerCondvar>,
}
pub struct ProcessorAsyncTask {
// worker_id代表的是当前异步任务对应的线程id
worker_id: usize,
// 在graph当中的节点位置
processor_id: NodeIndex,
// 全局的任务队列
queue: Arc<ExecutorTasksQueue>,
// 用于work-steal的调度唤醒策略
workers_condvar: Arc<WorkersCondvar>,
// 一个包装future,见下图的具体包装
inner: BoxFuture<'static, Result<()>>,
}
pub struct ExecutorTasksQueue {
// 记录当前执行任务队列是否完成
finished: Arc<AtomicBool>,
// 通知异步任务结束
finished_notify: Arc<Notify>,
workers_tasks: Mutex<ExecutorTasks>,
}
// 唤醒机制
struct WorkerCondvar {
mutex: Mutex<bool>,
condvar: Condvar,
}
执行模型的流程图如下:
四. 限时机制
限时机制其实是比较简单的,其主要的作用就是限制 sql 的 pipeline 执行的时间在规定时间内完成, 如果超时则自动终止.这个机制底层实现就是用了一个异步任务来跟踪,一旦超时就通知整个执行模型结束,这里对应的就是执行模型流程图里面的 finish。
以上便是 databend 的基于状态机和 work-steal 机制的并发调度模型实现.